This year I've attended the NumFocus Summit 2018 as the representative of Shogun.ML project at the Microsoft Technical Center, NYC. I've met many of the amazing maintainers and core contributors of NumFocus Sponsored projects. During the summit I've not only learned how important is for an outsider to have a roadmap (or rather a wish-list) for a project---stay tuned for more on our github page---, but thanks to Steve Dower I've learned about Azure Pipelines (for DevOps).
Finally a CI system that allows me the same flexibility that buildbot does, which we use extensively for Shogun. It allows depending on jobs, conditional tasks, templating etc. And most importantly, it supports Linux (including Docker), Windows and macOS builds. Basically almost all the OS that we usually test for in a PR or commit - one thing is still missing: ARMv7 arch.
Currently in our CI mess, we use Travis for Linux and macOS tests and AppVeyor for Windows builds. They served quite well in the past, but for example in both case being able to define dependencies among jobs is something that I've missed for years. In Shogun.ML, as you might know, thanks to SWIG we support many different language interfaces (e.g. Python, R, Ruby, JVM, C# etc.). These interfaces are basically shared libraries, that depend on the C++ (core) library of Shogun.ML. This means that for being able to compile any of the interface libraries, one would need to have the C++ (shared) library available. With our CMake setup, one could simply compile the C++ library (or install the binary):
mkdir build && cd build
cmake ..
make installOnce the shared library is available using the INTERFACE_<LANGUAGE> cmake flag one could compile the language interface library using the precompiled C++ library, without actually requiring to re-compile the whole C++ library from scratch (note: major versions should be the same). For example to compile the Python language interface against a precompiled C++ library, you would need to run the following commands:
mkdir build-python && cd build-python
cmake -DINTERFACE_PYTHON=ON -DLIBSHOGUN=OFF ..
make installThe CMake script will try to detect libshogun on your system. If the script cannot find it, it will throw an error, in this case setting the prefix path of the location of libshogun could be set with -DCMAKE_INSTALL_PREFIX=<path>.
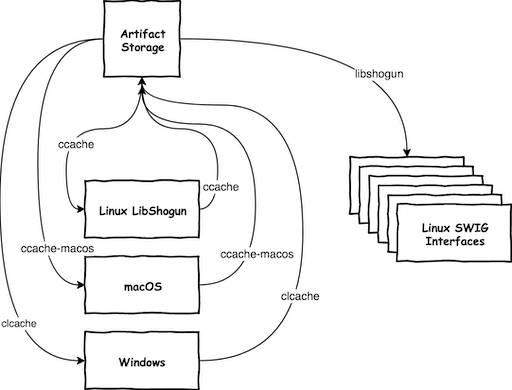
Now back to our CI problem: as in Travis defining dependencies between jobs is not possible, in all our CI jobs for all the interfaces we had to compile libshogun from scratch (see here). As you can see from the link this meant that we have 2 jobs for compiling and testing only libshogun (gcc and clang), and another 6 jobs to compile (and test) the language interfaces: Python, R, Java, C#, Ruby, Octave. But in case of all the 6 interface jobs we have to compile libshogun as well (not only the interface library). This is a waste of time and resources as we could actually use from one of the libshogun tasks the created shared library and just compile the interface library, if one could define a dependency between jobs. In Azure Pipelines with a simple dependsOn attribute I could define this dependency! The only tiny thing that I had to solve is to store somewhere the compiled shared libraries, which the SWIG jobs could access as well. Azure Pipelines has a storage for artifacts, that is more for release artifacts, but this served perfectly for me to store the shared libraries of the libshogun jobs for the SWIG jobs. I've created two small templates:
- archive-deploy: simply takes a directory to be archived and uploads it to the artifact storage under
artifactName. - download-extract: as it name says this template will download and artifact and extract its content to a specific location. Since there are two scenarios where we use this template, it got a bit more complex than one would expect in the first place. For the case that we explained till now, i.e. downloading an artifact that was generated by a triggering job (libshogun) this section of the script is the relevant one.
Using these templates, I've defined a libshogun job that compiles and tests the core C++ library using gcc and clang, and if all the tests passed, they would publish ccache-gcc and ccache-clang artifacts respectively. Once the libshogun jobs finished successfully they trigger the SWIG jobs, that will start with downloading the published libshogun artifacts and compile only the language interfaces.
Back to the second use-case of the download-extract template: on both our buildbot system and when developing shogun locally we extensively rely on ccache, which can significantly reduce compilation time of the library. Both in our Travis and AppVeyor jobs, we use ccache (or clcache) so that our CI jobs would be as fast as possible, since compiling shogun from scratch could take some time. Currently Azure Pipelines does not have an explicit task definition for adding ccache support to a job, hence I needed
to define this myself, which was rather easy as I just needed to
- setup the ccache environment (
CCACHE_DIR) - archive and publish the ccache directory content if the tests passed successfully
- in the new job download the previously published ccache.
The archiving and publishing of ccache directory is exactly the same as archiving and publishing of libshogun. Downloading of the ccache artifact is different though. Remember, in case of SWIG interfaces the jobs are triggered by libshogun jobs. Hence we could use the specificBuildWithTriggering variable in the DownloadBuildArtifacts task to identify the right artifact to download. In case of CCache artifacts things are a bit different: this section of the template is responsible to specify that the jobs should try to download the latest successful job's ccache artifact. So far developing this pipelines was rather straightforward, only couple of google/github searches were required to figure out how all the tasks works. This was the point where I ran into troubles, that isn't yet fixed while writing this article. Namely, in case of using buildType: 'specific' and buildVersionToDownload: "latest" attributes in DownloadBuildArtifacts task, it will simply fail if: there was not a single pipeline that finished with success. Note, the both of the stressed words:
- pipeline: not a single job, like libshogun, but the whole pipeline. So even though in case the compilation and test of the C++ library finished successfully, hence a ccache artifact is published, if any subsequent SWIG job (or the windows build) fails in the pipeline, this artifact will not be available for the
DownloadBuildArtifactstask as it requires the whole pipeline to finish successfully. - success: if any of the tasks ends with warnings, the whole pipeline (
Agent.JobStatusvariable) will be markedSucceededWithIssues, which is notSucceeded.
Note that DownloadBuildArtifacts simply fails if the specified artifact is not available (see the definition above what counts to be 'available'). If a tasks fails, by default it'll simply stop the execution of the job itself. That is actually a problem until the very first ccache artifact is ever published successfully, as until then the the whole job will fail. Of course there's a way to keep executing a job if a task fails. This could be done by setting continueOnError attribute to true for the task. Note, that although the job will be executed even though task with continueOnError failed, the whole pipeline will be marked SucceededWithIssues. Now this is becoming a catch-22. Although all the jobs ran successfully and published their ccache artifacts, since the DownloadBuildArtifacts will cause that the JobStatus is actually SucceededWithIssues, no subsequent runs of the pipeline will ever pick up those artifacts. In fact, for now for being able to use the ccache artifacts, for once I had to disable the DownloadBuildArtifacts task, so that the pipeline would finish with Succeeded. To overcome this issue there could be two say to fix this:
- patch the
DownloadBuildArtifactsso that it accepts artifacts fromSucceededWithIssuesjobs as well - create a new task that basically downloads the latest artifact regardless of the pipeline's status that produced it
As for the results, let the numbers speak for themselves:
- A pipeline without ccache ran for 1:03:32, that is more than an hour
- A pipeline with ccache ran for 13 minutes and 28 seconds.
So having ccache added to our jobs, we can run the pipeline 4.7 times faster than without!
There are still two things missing to make this pipeline 100%:
- Finish up the MS Windows build, that is being blocked at the moment by:
- Fixing mpack variant compilation errors: https://github.com/mpark/variant/pull/49
- Figure out why MKL is not detected by
FindBLAS.cmakeshipped with cmake
- Extend the pipeline to support PRs, namely that we want to have a job that runs our clang-formatter script to check for style problems, and make all the other job depending on this.
Azure Pipelines basically took all the flexibility of BuildBot and uses YAML for describing jobs. In my past experience I have found so many times to be the best descriptor of pipeline jobs. The bonus, all of it Azure Pipeline is based on TypeScript, which in my opinion is the best of combination of both statically typed languages and interpreted languages.